https://rfriend.tistory.com/284
[Python NumPy] 무작위 표본 추출, 난수 만들기 (random sampling, random number generation)
이번 포스팅에서는 시간과 비용 문제로 전수 조사를 못하므로 표본 조사를 해야 할 때, 기계학습 할 때 데이터셋을 훈련용/검증용/테스트용으로 샘플링 할 때, 또는 다양한 확률 분포로 부터 데
rfriend.tistory.com
seed: 난수 생성 초기값 부여
size:샘플 생성(추출)개수 및 array shape설정
1-1) 이항분포로부터 무작위 표본 추출
np.random.binominal(n,p,size)
1-2)초기하분포에서 무작위 표본 추출
np.random.hypergeometric(ngood,nbad,nsample,size)
1-3)포아송분포로부터 무작위 표본 추출
np.random.poisson(lam,size)
2-1)정규분포로부터 무작위 표본 추출
np.random.normal(loc,scale,size)
(2)연속형 확률분포(continuous probability distribution)
2-1)정규분포(normal ditribution)로부터 난수 생성
#Draw random samples from a normal (Guassian) distribution
#np.random.normal(loc=0.0, scale=1.0, size=None)
#mu: Mean("centre") of the distribution
#sigma: Standard deviation (spresd or "width") of the distribution
#size: Output shape
평균이 '0', 표준편차가 '3'인 정규분포로부터 난수 100개를 생성해보고, 히스토그램을 그려서 분포를 bin구간별 빈도(frequency)와 표준화한 비율(normalized percentage)로 살펴보겠습니다.
(여기서 평균과 표준편차의 의미?)
np.random.seed(100)
mu,sigma= 0.0, 3.0
rand_norm = np.random.normal(mu,sigma,size=100)
rand_normOut[29]:
array([-5.24929642, 1.02804121, 3.45910741, -0.75730811, 2.94396236,
1.54265652, 0.66353901, -3.21012999, -0.56848749, 0.76500433,
-1.37408096, 1.30549046, -1.75078515, 2.45054122, 2.01816242,
-0.31323343, -1.59384113, 3.08919806, -1.31440687, -3.35495474,
4.85694498, 4.62481552, -0.75563742, -2.52730721, 0.55355607,
2.8112466 , 2.19300103, 4.08466838, -0.97871418, 0.16702804,
0.66719883, -4.32965099, -2.26905692, 2.44936203, 2.25133428,
-1.36784078, 3.5688668 , -5.07185048, -4.06919715, -3.69730354,
-1.63331749, -2.00451521, 0.02194369, -1.83881621, 3.89924422,
-5.19928687, -2.9499303 , 1.07252326, -4.84073551, 4.4121416 ,
-3.56405279, -1.64923858, -2.82013848, -2.48379709, 0.3265904 ,
1.52342877, -2.58668204, 3.74840923, -0.23883374, -2.66919444,
-2.64539517, 0.05591685, 0.71353387, 0.04064565, -4.9065882 ,
-3.13262963, 1.83911665, 2.20861564, 3.08076432, -4.29657183,
-5.5235649 , 1.09827968, -0.99533141, -2.06765393, 6.10382268,
-1.65214324, 2.25135999, -3.92097702, 1.74172001, -3.31356928,
2.07036441, 2.0606702 , -4.70006259, 2.71492236, 2.3364672 ,
1.28469861, 0.32661597, 0.0848509 , -1.73647747, -3.5983536 ,
-5.11785602, 1.10749187, 5.62972028, -1.13071005, 5.49580825,
0.0090523 , -0.2280704 , 0.01187278, -0.55504233, -7.46145461])
count, bins, ignored = plt.hist(rand_norm, normed=False)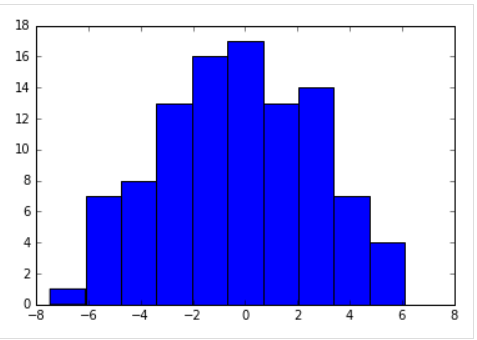
2-2) t분포로부터 무작위 표본 추출: np.random.standard_t(df,size)
자유도가 3인 t-분포로부터 100개의 난수를 생성하고 히스토그램 그리기
# t-분포로부터 난수 생성
# Draw samples from a standard Student's distribution with df degrees of freedom
# np.random.standard_t(df,size=None)
# df: Degree of freedom
# size: Output shape
np.random.seed(100)
rand_t = np.random.standard_t(df=3, size=100)
In [35]: rand_tOut[35]:
array([-1.70633623, 0.61010003, 0.45753218, -0.85709656, -0.42990712,
-0.7437467 , 0.8444005 , -0.4040428 , 2.13905276, -0.10844638,
0.67238716, 1.88720362, -2.57340231, -0.69724955, -3.40107659,
-0.57745433, -0.36487447, 3.95862541, 2.34665412, -0.94310449,
0.81852816, -0.48391289, 0.01380029, -0.43003718, -2.25784604,
-0.18216847, -1.21433582, 0.46347964, 0.50024665, -1.1595865 ,
0.02358778, -1.18879826, -0.38767689, 2.24289791, -2.80798472,
-2.838893 , -0.39222432, -1.61499121, -1.78498184, 0.44618923,
-1.5181203 , 5.44389927, 4.17743903, -0.49617121, -0.02996529,
0.89595015, 1.14860485, -3.16541308, 0.14279246, 0.83121743,
-0.32403947, 0.59297222, -0.39750861, 0.57634934, 0.81587478,
-1.29367024, -0.28580516, -0.48422765, -0.83697192, 0.50702557,
-1.98915687, 2.92965716, -1.19522074, 0.65511251, 2.12055605,
-0.03640814, -0.41931018, 3.31199804, -0.61725596, 0.79681204,
1.86805014, -0.54345259, 3.11909936, 0.86410458, 2.66353682,
0.23735454, -0.76306875, 0.24471792, -0.13515045, 0.26402784,
4.68946895, 0.70573709, -0.17783758, 1.85205955, -0.18352788,
-0.65713104, -0.73674278, 2.16549569, 1.22326388, -0.5112858 ,
-1.54451989, -1.73428432, 0.46947115, 1.66594804, 0.51687137,
1.51361314, -2.22193709, 0.89557421, 0.56222653, -0.55564416])
'개념 정리 > 문법 정리' 카테고리의 다른 글
| 객체,클래스,인스턴스의 차이 (0) | 2022.07.04 |
|---|---|
| ndarrya 클래스 (0) | 2022.07.03 |
| loc(다중조건) (0) | 2022.07.03 |
| 행 항목 이름 바꾸기 (0) | 2022.06.22 |
| DataFrame 대소문자 구별 잘하기 (0) | 2022.06.22 |